
티스토리 뷰
들어가며
이번 회고록은 빅데이터 분석 수업에서 진행한 프로젝트에 대한 이야기입니다.
여행을 좋아하는 저는 여행 관련 데이터셋을 활용해 유의미한 인사이트를 도출하고자 했습니다. 특히, 국내 서부권 지역은 주로 자연 관광지로 유명하기 때문에, 경제 상황이 비슷하고 지역별 물가가 유사할 것이라는 가설을 세웠습니다.
따라서 이러한 가설을 바탕으로 다양한 분석을 시도했지만, 족족 예상이 빗나가 성공과 실패가 모호한 프로젝트가 되었습니다.
그럼에도 불구하고, 최대한 유의미한 인사이트를 얻어보고자 탐색적 데이터 분석(EDA)에 심혈을 기울여 부족한 부분을 최대한 보완하고자 노력해보았습니다.
프로젝트 목표
서부권 관광 데이터 분석을 통해 여행자들의 소비 패턴을 파악하고, 지역 관광 산업의 발전을 위한 인사이트를 도출하는 것입니다. 이를 통해 지역 경제에 기여할 수 있는 전략을 수립하고자 하였습니다.
데이터셋
한국관광 데이터랩
한국관광데이터랩, 한국관광 데이터랩, 관광빅데이터, 관광빅데이타, 관광통계
datalab.visitkorea.or.kr
가설
1. 이동거리가 긴 여행자일수록 소비가 더 높을 것이다.
2. 여행 기간이 긴 여행자일수록 저렴한 숙박업소를 선호할 것이다.
3. 특정 인원수에서 소비금액이 급증할 것이다.

GPS 데이터 통합
설문에 참여한 관광객들의 데이터 정보를 비교하기 위해 GPS 데이터를 통합하고, 4000개의 샘플 데이터를 추출해 folium 라이브러리로 마커 클러스터를 표시해주었습니다.
# ZIP 파일 경로
gps_file_path = '/content/drive/MyDrive/data/raw/TL_gps_data.zip'
# 저장할 파일 경로
gps_combined_csv_path = '/content/drive/MyDrive/data/raw/combined_gps_data.csv'
# ZIP 파일을 열고 파일 목록을 확인
with zipfile.ZipFile(gps_file_path, 'r') as zip_ref:
file_list = zip_ref.namelist()
# CSV 파일들만 추출 (필요에 따라 조정)
csv_files = [file for file in file_list if file.endswith('.csv')]
# 각 CSV 파일을 읽어서 데이터프레임으로 변환
dataframes = []
with zipfile.ZipFile(gps_file_path, 'r') as zip_ref:
for csv_file in csv_files:
with zip_ref.open(csv_file) as file:
df = pd.read_csv(file)
dataframes.append(df)
# 모든 데이터프레임을 하나로 통합
combined_df = pd.concat(dataframes, ignore_index=True)
# 통합된 데이터프레임을 CSV 파일로 저장
combined_df.to_csv(gps_combined_csv_path, index=False)# 데이터 샘플링 (4000개)
sample_data = combine_gps_data.sample(n=4000, random_state=42)
# 지도 초기화 (중심 좌표 설정)
map_center = [sample_data['Y_COORD'].mean(), sample_data['X_COORD'].mean()]
m = folium.Map(location=map_center, zoom_start=7)
# 마커 클러스터링 추가
marker_cluster = MarkerCluster().add_to(m)
# 샘플 데이터 마커 추가
for idx, row in sample_data.iterrows():
folium.Marker(
location=[row['Y_COORD'], row['X_COORD']],
popup=f"ID: {row['TRAVEL_ID']}<br>Time: {row['DT_MIN']}",
icon=folium.Icon(color='blue', icon='info-sign')
).add_to(marker_cluster)
# 지도
m
가장 큰 소비패턴
TRAVEL과 ACTIVITY_CONSUME, SGG_CODE 테이블을 결합해 서부권에서 가장 큰 소비패턴이 나타나는 지역을 출력해주었습니다.
# 필요한 컬럼의 데이터 결합
activity_consume = activity_consume[['TRAVEL_ID', 'SGG_CD', 'PAYMENT_AMT_WON', 'ACTIVITY_TYPE_CD']]
travel = travel[['TRAVEL_ID', 'TRAVEL_START_YMD', 'TRAVEL_END_YMD']]
sgg_code = sgg_code[['SGG_CD', 'SGG_NM']]
# TRAVEL 테이블과 ACTIVITY_CONSUME 테이블 결합
travel_activity = pd.merge(travel, activity_consume, on='TRAVEL_ID')
# TRAVEL_ACTIVITY 테이블과 SGG_CODE 테이블 결합
travel_activity_sgg = pd.merge(travel_activity, sgg_code, on='SGG_CD')
# 시군구별 총 소비 금액 계산
region_expense = travel_activity_sgg.groupby('SGG_NM')['PAYMENT_AMT_WON'].sum().reset_index()
max_expense_region = region_expense.loc[region_expense['PAYMENT_AMT_WON'].idxmax()]
print(f"가장 큰 소비 패턴이 나타나는 지역: {max_expense_region['SGG_NM']}")
print(f"소비 금액: {max_expense_region['PAYMENT_AMT_WON']}")
가장 큰 소비 패턴이 나타나는 지역은 여수시로 확인되었습니다.
이에, 여수시의 어떤 활동 유형이 가장 많은 비중을 차지하는지 분석해보았습니다.
- 1: 취식
- 2: 쇼핑/구매
- 3: 체험활동/입장
- 4: 단순구경/산책
- 5: 휴식
- 6: 기타활동
# 필요한 컬럼의 데이터 결합
activity_consume = activity_consume[['TRAVEL_ID', 'SGG_CD', 'PAYMENT_AMT_WON', 'ACTIVITY_TYPE_CD']]
travel = travel[['TRAVEL_ID', 'TRAVEL_START_YMD', 'TRAVEL_END_YMD']]
sgg_code = sgg_code[['SGG_CD', 'SGG_NM']]
# TRAVEL 테이블과 ACTIVITY_CONSUME 테이블 결합
travel_activity = pd.merge(travel, activity_consume, on='TRAVEL_ID')
# TRAVEL_ACTIVITY 테이블과 SGG_CODE 테이블 결합
travel_activity_sgg = pd.merge(travel_activity, sgg_code, on='SGG_CD')
# 여수시 데이터 필터링
yeosu_data = travel_activity_sgg[travel_activity_sgg['SGG_NM'] == '여수시']
# 활동유형코드별 데이터 집계
activity_type_counts = yeosu_data['ACTIVITY_TYPE_CD'].value_counts()
# 파이 차트 생성
plt.figure(figsize=(10, 7))
activity_type_counts.plot.pie(autopct='%1.1f%%', startangle=140, colors=plt.cm.Paired.colors)
plt.title('여수시에서 여행한 사람들의 활동유형코드 분포')
plt.ylabel('') # y축 레이블 제거
plt.show()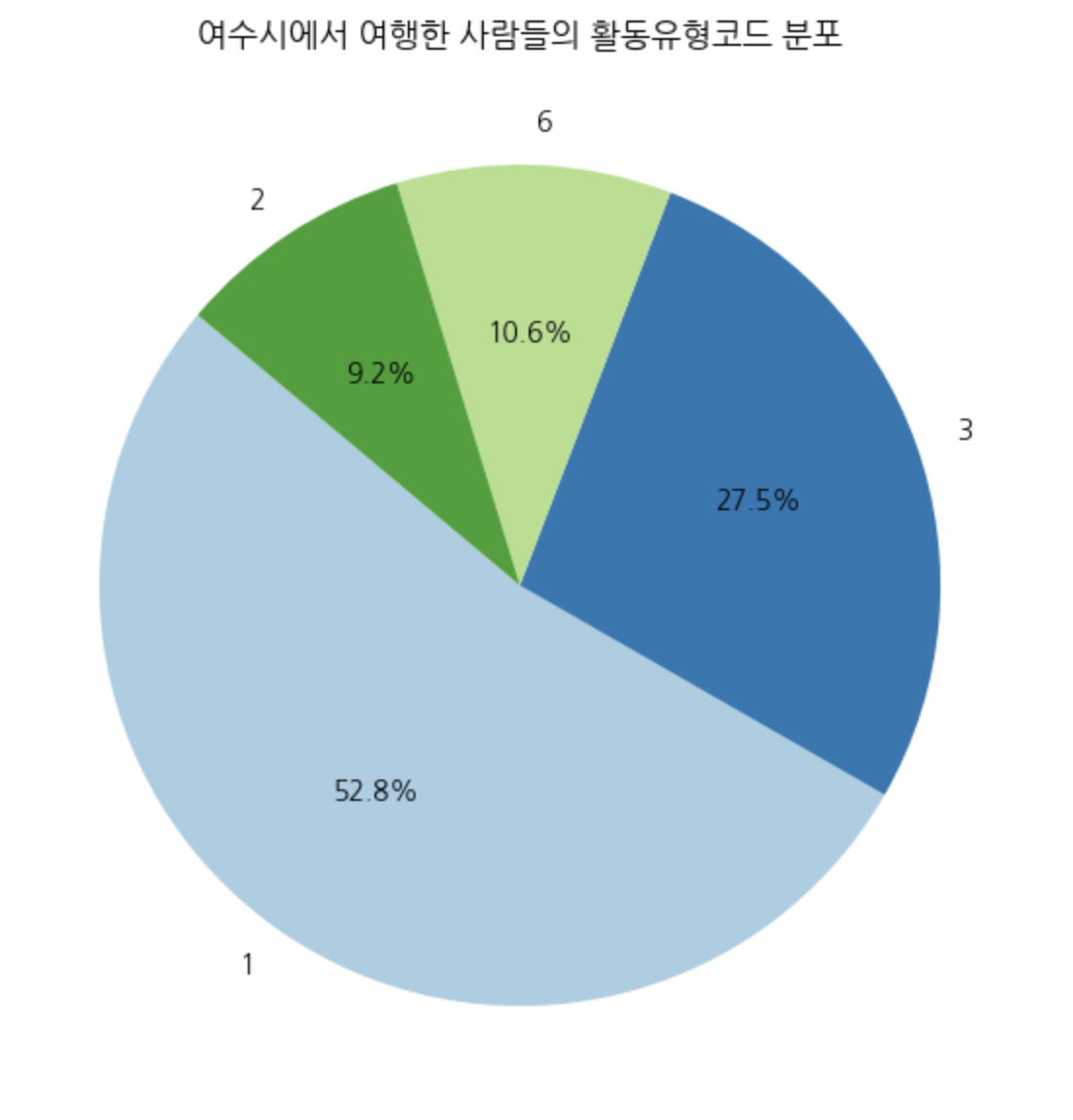
취식에서 압도적인 비율을 차지하고 있는 것을 알아냈습니다.
그 다음으로 체험/입장과 기타활동, 쇼핑이 뒤를 이었습니다.
여행자 이동 패턴과 활동 소비의 상관 관계
저는 여행자 이동거리가 길수록 활동 소비가 높을 것으로 판단했습니다. 교통 시간이 멀수록 두 번은 못 온다는 보상심리가 나타나 많은 금액을 소비할 것으로 판단했기 때문입니다.
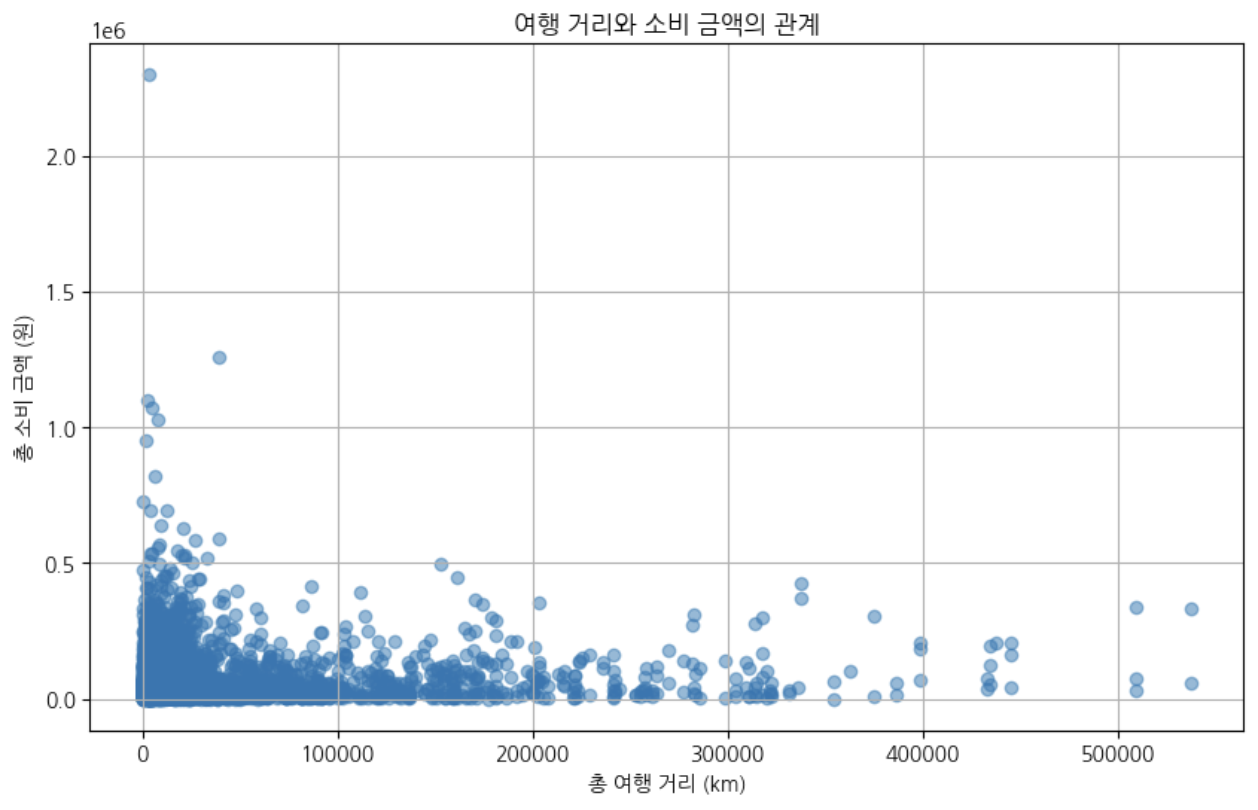
하지만 뚜렷한 관계를 찾기 어려웠으며, 오히려 이동거리가 긴 소비자가 더 낮은 소비 금액을 소비한 것으로 보이는 결과가 나타났습니다. 장거리 여행자는 소비 금액이 낮아보이지만, 단거리 여행자는 소비자별 소비 금액에서 큰 차이가 보입니다.
여행 기간과 숙박패턴의 상관 관계
저는 여행 기간이 길어질수록 관광객이 여행비에 부담을 느껴, 더 저렴한 숙소를 선호할 것이라는 가설을 세웠습니다. 이를 분석하기 위해 TRAVEL 테이블과 LODGING_CONSUME 테이블을 결합해주었습니다.

여행 기간이 길수록 숙박 비용의 분포가 좁아지며, 2~4일차 소비자는 소비자에 따라 편차가 큰 경향을 띄고 있습니다. 전반적으로 유의미하다고 판단될정도의 상관관계는 보이지 않습니다.
동반자와 소비 패턴의 상관 관계
동반자가 많을수록 총 여행 소비 금액이 늘며, 특정 지점에서 급격한 변화가 있을 것으로 예상했습니다. 다인원이 모이기 쉽지 않으니 일종의 보상심리가 작용하며, 여행 특성상 짝수보다 홀수 인원이 더 많은 돈을 지불하는 것처럼 특정 인원에서 숙박 시설이 나뉘게 되고, 소비 금액이 급등하는 구간이 있을 것으로 판단했기 때문입니다.

동반자수가 증가할수록 소비 금액의 중앙값이 상승하는 경향을 보이며, 10명에서 소비 금액이 급격히 증가합니다. 동반자수가 많아질수록 변동성이 커집니다.
해당 프로젝트 진행 과정이 담긴 Colab 링크입니다.
서부권 여행자 소비 패턴 분석 및 인사이트 도출.ipynb
Colab notebook
colab.research.google.com
마치며
본 프로젝트는 서부권 여행자 소비 패턴을 분석하고자 시작하였습니다. 따라서 여러 가설을 세워, 의미 있는 상관관계를 도출하려는 시도를 했습니다. 하지만 분석을 진행하면서 초기 가설이 예상만큼 유의미한 관계를 나타내지 않았습니다.
이 과정에서 초기 가설과 데이터셋의 선정 중요성을 깨닫게 되었습니다. 해당 프로젝트에서는 가장 큰 소비패턴이 보여지는 여수시에 집중함으로써 관광객들이 가장 좋아하는 소비 종목을 분석함으로써 유연한 접근의 중요성을 깨닫게 되었습니다.
'Oops, All Code! > 📝 Study Notes' 카테고리의 다른 글
| [GitHub] pull push하는 법 (0) | 2024.07.02 |
|---|---|
| [GitHub] 원격 저장소에 연결하기 (0) | 2024.07.02 |
| [Git] fatal: The current branch main has no upstream branch. 에러 (0) | 2024.06.01 |
| [Git] 작업 되돌리기, 스테이징 되돌리기, 커밋 되돌리기, 특정 커밋으로 돌아가기 (1) | 2024.05.31 |
| [GitHub] error: cannot run notepad++: No such file or directory 혹은 힌트: 편집기가 파일을 닫기를 기다리는 중입니다... 에러 (1) | 2024.05.30 |
- Total
- Today
- Yesterday
- typescript
- 플리마켓후기
- 비즈플리마켓
- 카페추천
- 도서추천
- 플리마켓운영
- 트러블슈팅
- 안성스타필드
- 코딩테스트
- javascript
- 어휘력
- 서평
- 어른의어휘공부
- 대학생팝업스토어
- 책추천
- 카드뉴스
- 소사벌
- 대학생플리마켓
- js
- 타입좁히기
- 회고
- 도서리뷰
- react
- 소사벌맛집
- 프론트엔드
- 프로토타입
- 경험플리마켓
- 일급객체
- 프리코스
- 우아한테크코스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |